
Exceptional Performance Cloud Built for AI Workloads
Managed cloud, inference API, or bare metal access. Same infrastructure. Your choice.
Kubernetes-native cloud for teams who want full control without infrastructure overhead.
Focus on building models, not managing infrastructure. Our platform handles everything from GPU allocation to load balancing, so you ship AI products faster without a DevOps team.
Scales on actual workload. 3-5x faster container spin-up. Handles traffic spikes 8-10x faster.
Standard K8s API, Helm charts, as well as familiar workflows. Native GPU scheduling and isolation.
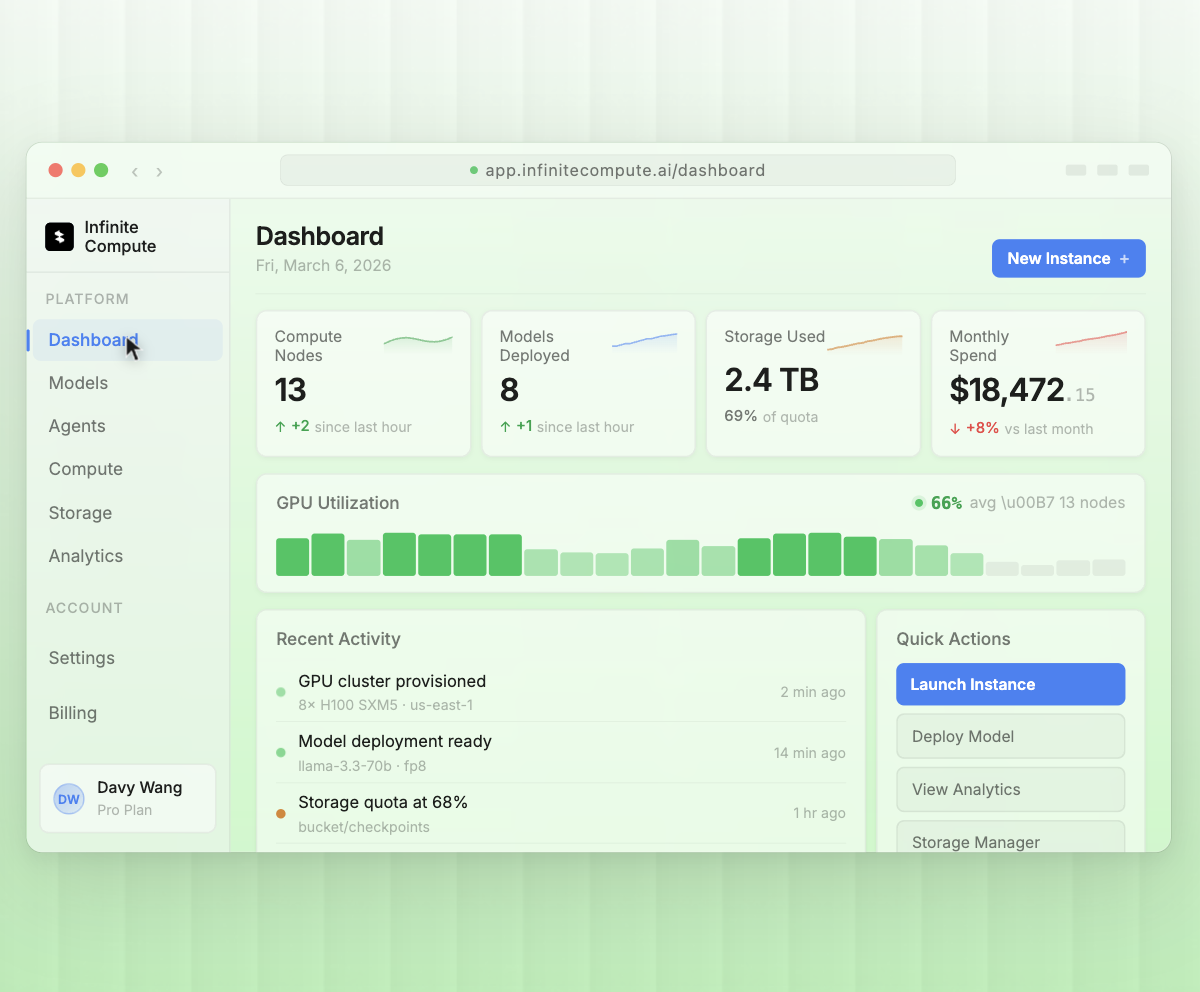
Intelligent load balancing, Automatic failover and Real-time performance. Monitoring 94% average GPU utilization
Intelligence on Demand
Production-ready endpoints for Llama 3.3, Mistral, DeepSeek, and frontier models. Automatic scaling handles traffic spikes. No GPU management, no surprise bills—just intelligence on demand.
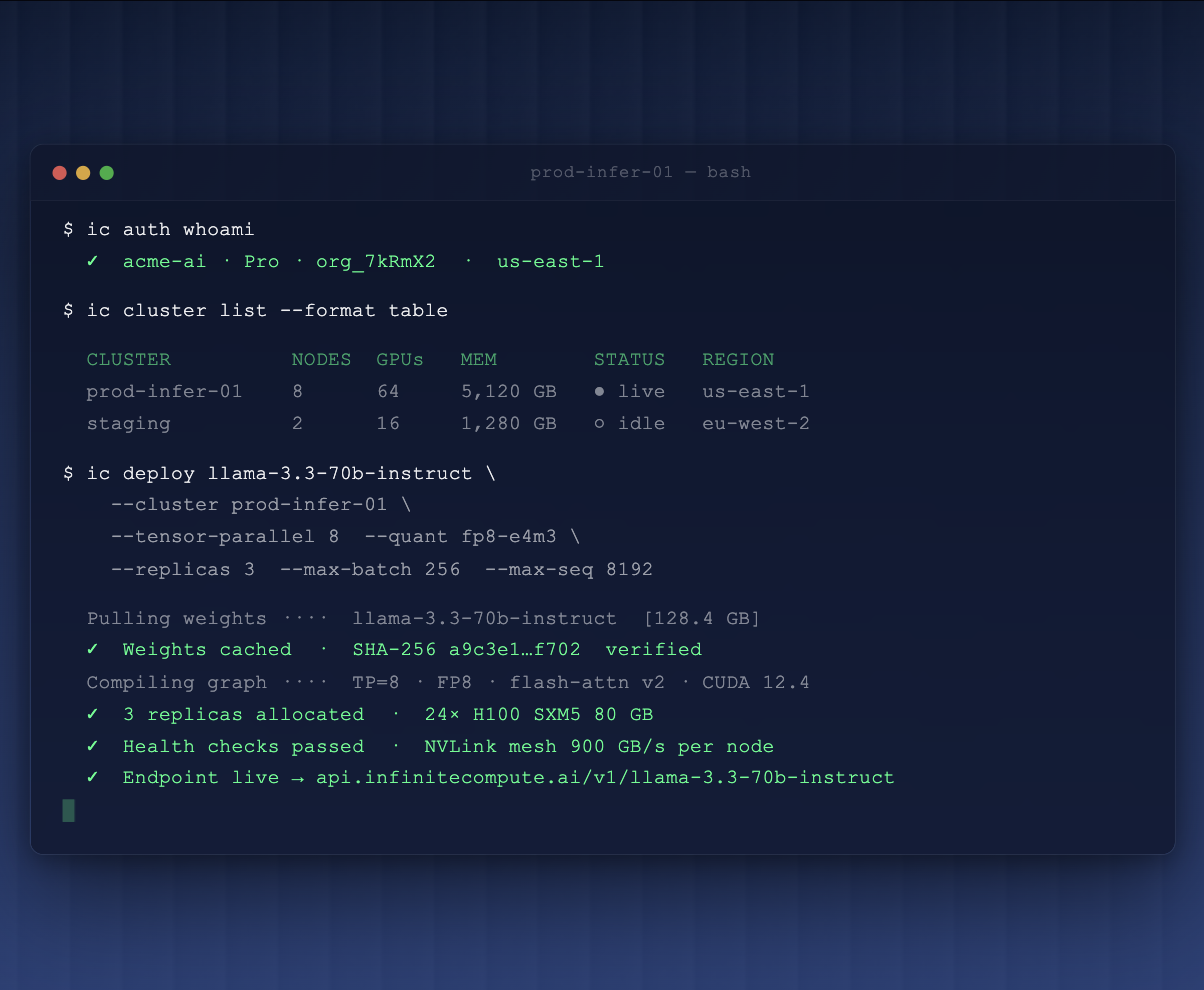
Pre-configured environments and familiar tools
Enjoy the convenience of one-click Jupyter access and effortlessly connect to the GPU instances from your browser. Benefit from pre-installed popular ML frameworks like Ubuntu, TensorFlow, PyTorch, CUDA, and cuDNN, all readily available.







Ready to Build at Scale?
Whether you need instant API access to frontier models or a 100,000-GPU supercluster, our engineering team is ready to architect your solution.